In modern distributed systems, reliable and consistent event processing is crucial for maintaining data integrity and ensuring system stability. One of the common challenges is handling duplicate messages. Some patterns like an Outbox pattern and Sagas ensure reliable message delivery, but the message broker can deliver the same message multiple times. Many messaging systems have built-in mechanisms to eliminate duplicate messages, but due to network failures or failing to send acknowledgement and retry mechanisms, a consumer service can still receive duplicate messages.
Before moving forward, let’s take a look at the delivery guarantees from message brokers. In general, there are three types of guarantees:
- at most once – consumer receives a message once or possibly not at all
- at least once – consumer receives a message once or possibly multiple times
- exactly once – producer sends exactly once and the message is delivered to consumers exactly once, excluding failures and retries, and is considered the most complex delivery guarantee
The most common guarantee among message brokers is at least once delivery. This type does not consider the message processed until the consumer acknowledges the delivery. There are many cases where acknowledgement is not sent to the message broker:
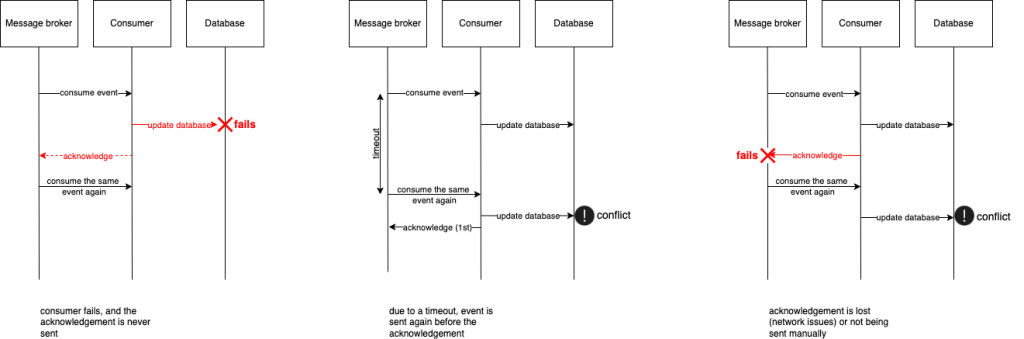
- consumer fails and the acknowledgement of delivery is never sent to the broker. The broker will resend the message
- generally there are timeouts that an acknowledgement needs to be sent. If the acknowledgement is not sent in that time frame, the broker will consider the unacknowledgement and send the message again
- acknowledge is not sent due to a network failure
- some libraries or implementations requires manual acknowledgement in the code, and if for any reason it never occurs, the message will be send again
The scenarios are demonstrated on the diagram below.
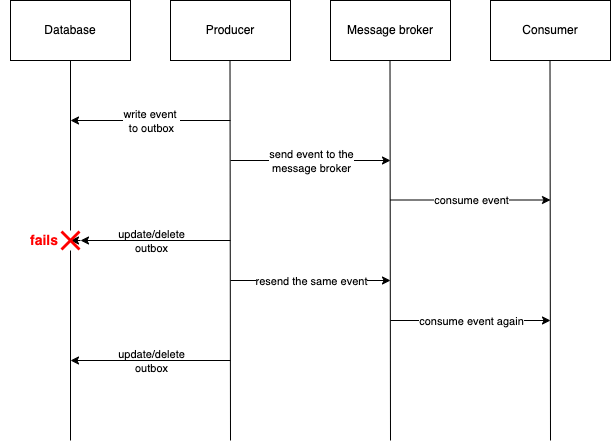
Another reason for receiving duplicate messages is because the producer is sending the same message more than once. It can be due to a bug, but there is also a possibility that the Outbox pattern will send the same message more than once due to its design. It ensures at least once delivery and if it sends a message to the broker but fails to update its database, it will send the same message again. The following diagram demonstrates this case.
Processing duplicate messages can lead to data corruption, redundant operations and violations of business rules, and therefore it is important for consumers to implement mechanisms that prevent those issues. A service that can safely consume the same message multiple times is called an idempotent consumer. Idempotency is a term that in mathematics describes a function that produces the same result if it is applied to itself (Hohpe and Woolf, 2023). In the concept of interservice communication, this concept translates into a message that has the same effect whether it is received once or multiple times.
A service is considered an idempotent consumer if it can safely process the same message multiple times without causing unintended effects (Richardson, 2019). One way to implement an idempotent consumer is through the Eventuate Tram framework, which ensures idempotency by recording unique identifiers of processed messages. It maintains a PROCESSED_MESSAGES table as part of the local ACID transactions used by the business logic, enabling reliable detection and discarding of duplicates (Richardson, 2019). Alternatively, idempotency can be achieved through explicit de-duplication, which involves maintaining a buffer of unique message identifiers to identify and ignore duplicates, or by designing message semantics to inherently support idempotency (Hohpe and Woolf, 2023). The latter approach avoids repeated side effects by structuring message content to specify a desired state rather than an action, such as setting a balance to 110 instead of adding 10 to the balance.
Based on those theoretical findings, we need to structure the event messages so that they cannot violate business rules when being processed multiple times, and/or keep a record of processed events. As we explained, application logic is idempotent if calling it multiple times with the same input values, it has no effect. An example of an idempotent message is cancelling an order; if we cancel an already cancelled order, there is no difference. We have to be a bit more careful with creating an order. If we provide order id, we can use this field as a unique constraint and the same order will not be created twice. Those messages are considered safe, as processing them multiple times won’t cause harm. Unfortunately, all the messages are often not idempotent, and in this case we must implement a mechanism for tracking messages on the consumers (Richardson, 2019).
Tracking consumed messages is one of exactly once delivery strategies, and it requires messages to have some kind of a unique identifier, let’s call it message id, to check if the message was consumed. If message id is stored, it can be compared with new messages and any duplicates can be discarded. With relational databases, we can use a separate table to track messages. When a message id is saved, the business logic should be updated within the same transaction. If a message id exists, the whole transaction, including updating the business entity, will fail due to a unique database constraint on the message id. A pseudocode demonstrating this approach is following:
begin transaction;
update business entity from a message payload;
save message id from the message;
end transaction;The limitation of this approach is that it only works on relational databases. Many NoSQL databases don’t support transactions or have limited support for transactions when updating two tables, and we cannot rely on this approach. A possible solution is to track message ids in any available application table, and changing the business logic to perform a manual check if the message was processed (Richardson, 2019).
A diagram above demonstrates what can go wrong if we are not using the same transaction when tracking message ids and updating business logic. As shown, we updated the business entity and failed to insert a message id. When the same message is consumed again, the check will consider the message not to be processed and the service will update the business entity again, which can cause conflicts or inconsistent state. We can separate tracking and processing logic into two separate processes as we will demonstrate in the next architectural principle, the inbox pattern.
Inbox pattern
To keep a record of processed events, we need some kind of storage, it can be a simple in-memory buffer or a database table. When the consumer receives an event, it needs to check in the storage if the event was processed, which is usually done by comparing the event’s unique identifier. If the event was not processed, it should be stored and processed, otherwise, if the event was processed, it should be discarded.
Inbox pattern enhances this process of message storage on the consumer side. It has a dedicated table to store incoming messages. When a new message is consumed, it is not processed immediately, but stored into this inbox table, and the acknowledgement is sent to the message broker. Then another process, a scheduler for example, scans the table for new, unprocessed messages. New messages are processed in a separate thread than consumed, and once processed, the record in the inbox table is either updated or removed. It looks similar to the outbox patterns, the difference is that it works in the opposite direction.
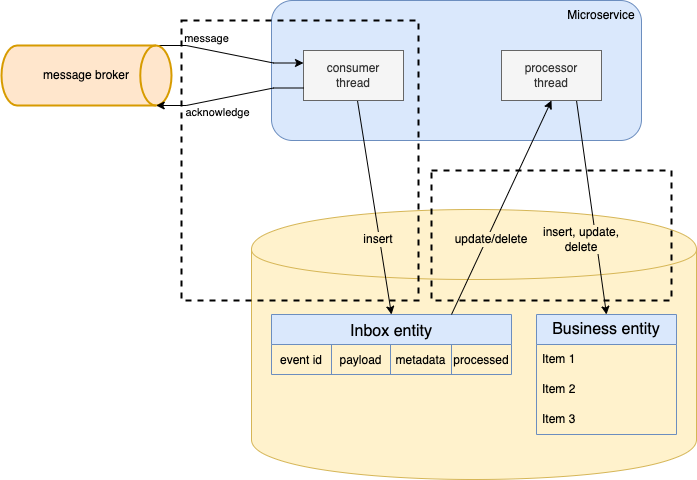
The inbox table should at least contain fields for the unique identifier, the payload and a flag to mark events as processed. Unique identifier, or message id, makes sure that the incoming messages are de-duplicated. If the application crashes after saving a duplicate message id, the acknowledgement will not be returned and the message will get resend. To prevent this issue, we should perform a check if a message id already exists in the database and discard duplicates at this point.
Inbox pattern can be helpful in case the order of messages is important. Some message brokers guarantee the order of messages, but not all of them. If the messages are stored in a database and have an increasing identifier, the order can be restored by the process which processes the messages. Keeping the order of the messages in the inbox table can be useful when some messages are missing for some reason. In such cases, we can launch a redelivery strategy by manually asking the producer to send all the messages from the missing offset again.
This pattern brings benefits like ensuring exactly once delivery by providing a de-duplication mechanism, it helps maintain the order of the messages and can be used for auditing purposes from the log of received messages.
On the downside, the index pattern adds additional complexity, more load to the database and increases latency. Some performance optimizations can mitigate those obstacles, like introducing parallelism with multiple schedulers concurrently scanning the inbox table and processing messages or starting processing asynchronously immediately after inserting it into the inbox table. In case of concurrency we have to make sure that the locks are used to prevent other threads from processing the same rows. Lastly, to prevent the inbox table from growing too much, processed messages can be deleted regularly.
References
- Hohpe, Gregor, and Woolf, Bobby. Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions. Addison-Wesley, 2003.
- Richardson, Chris. Microservices Patterns. Manning Publications, 2019.
- Atlasik, Krzysztof. “Microservices 101: Transactional Outbox and Inbox.” Software Mill, 2022, https://softwaremill.com/microservices-101/
- Comartin, Derek. “Handling Duplicate Messages (Idempotent Consumers).” CodeOpinion, 2020, https://codeopinion.com/handling-duplicate-messages-idempotent-consumers
- Ludwikowski, Andrzej. “Message delivery and deduplication strategies” Software Mill, 2022, https://softwaremill.com/message-delivery-and-deduplication-strategies/