In the traditional monolith systems all the operations are performed on a single database. While it is very simple, it has some limitations, particularly scalability and performance related. In case there are multiple operations that are running concurrently, for example if we want to read some data while the write operation has not finished yet, the read operation will have to wait. Also if we take a look at the database query that needs to join several tables, it can cause deadlocks and the database will not be able to process all the transactions.
The Command Query Responsibility Segregation (CQRS) tries to solve those issues and it is one of the most important patterns in the microservice architecture. It is used to avoid complex queries and ineffective relations between tables by splitting read and write operations. This principle follows the separation of concerns principle. Usually two separated databases are used in this pattern, one for reading and the other for writing data. A good practice here is to have those two databases physically separated and each one of them is customized to its needs, for example a relational database for writing data and NoSQL database for reading. The diagram below shows the high-level overview of the CQRS pattern.
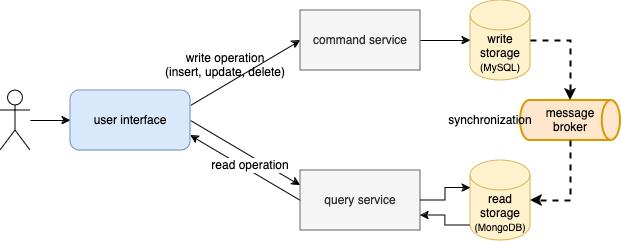
Having two independent databases has another advantage, that is we can independently scale them. For example if we have a system that usually requires more read operations, the database for reading can be scaled independently of the write database. It is just a matter of adding additional replicas for a read database. Moreover, the data model for read operations can be customized. With this approach, we can optimize models to reduce the number of relations and we can easily extend the models with new fields.
When having separated databases for reading and writing, the main concern is how to synchronize the databases. Ideally we want to keep the data synchronized and consistent all the time. The most convenient solution lies in the event-driven architecture which is based on event publishing. With each write operation an event is generated and published to the message broker. After it is published, a service consumes this event and updates the read database. However we have to keep in mind that the changes are not instant. There is a slight delay between publishing and consuming the event. This is known as eventual consistency.
The CQRS pattern consists of two concepts: commands and events. Commands are used to change the entity state which triggers writing to a database. The events are used to track changes and transfer those changes to the other parts of the system, components responsible for reading data. Operations are split into two parts: the command and the query layer. Commands are used to create, update or delete data, while queries are used to retrieve data.
Let’s take a look at some of the benefits CQRS pattern has:
- It enables efficient implementation of the queries from multiple sources. The read part of the data storage is optimized for efficient reading operations, and the event-driven architecture takes care that the data is synchronized. This enables us to get rid of the consuming reading operations from multiple sources
- Ensures the system is highly scalable. Because read and write data storage are separated, they can be scaled independently
- It brings flexibility regarding data models and queries, and loose coupling. Each service can modify the models so that the effective queries for particular needs can be easily implemented
- It uses the separation of concerns principle. In the CQRS pattern, the commands and queries are separated which eases the maintenance and improves the scalability of each component in the system
- Different technologies can be used in this pattern. It is not necessary for reading data storage to use the same technology as the writing one.
On the other hand, there are some drawbacks. The architecture is more complex, because developers need to implement additional services for queries, which need to be maintained. One of the biggest drawbacks of the CQRS pattern is the latency between commands and queries. A possible scenario which can happen is when the application updates its state and the changes are not synchronized in time. The query that reads data can return older versions of the data. To mitigate this issue, we can use the principle of versioning. When updating the entity, the version field is increased with each update and returned to the client in the queries.
Use cases
The CQRS pattern is useful in high-traffic systems and in cases where many users are accessing the same data in parallel. It is beneficial when we need to optimize read operation and we are dealing with retrieving data from multiple sources. In this case, the CQRS pattern can be applied to consolidate data read models and limit complex queries. On the other hand, this pattern is not suitable in scenarios where business rules are simple or when we are dealing with basic CRUD operations for data access because of the complexity of this pattern, which may outweigh the benefits of its use in such straightforward cases.
Combining CQRS with other architectural patterns
The CQRS works well in a combination with Event Sourcing pattern. The command level of the CQRS pattern can be used to process changes and generate events that can be used to create an application state. Another benefit of combining those two patterns is that the application log doesn’t need to be queried directly. We can use the projections, which are part of the query level of the CQRS pattern. This enables us to use application log for auditory purposes and is suitable in cases where a high amount of changes are written into the log.